Disclaimer: It’s been a while since I worked on an active data centre project (6, 7 years? Which is an eternity in such a fast moving field) so there are probably be areas below where industry practice has moved on, if you spot any errors or questionable assumptions please let me know and I’ll happily update my blog!
The other morning I woke up and read some news about how the UK PM is splashing $100M on ‘UK AI Supermodels’. It’s a good article, and it talks about the previously announced plan to build a UK supercomputer (presumably to run said models). The ever impressive Ian Hogarth has been put in charge of the group developing the models, but there isn’t any detail on the hardware yet. Whether it all actually happens remains to be seen, but it got me thinking about how you could hypothetically build such a machine, and what it would be like as a project (spoiler, I’m part way through the excellent How Big Things Get Done by By Bent Flyvbjerg and Dan Gardner). Anyone who’s been paying attention for the last decade or two should be well aware that IT projects can turn into giant fail whales, so there is clearly a high probability of failure from the outset.
The most interesting supercomputer I’ve seen recently is the Tesla Dojo. It is interesting in a number of ways, specifically:
- Custom chips
- Cheap/cost effective
- AI focused
If the objective is to be a UK ‘homemade’ supercomputer, the main problem will be chip fabrication. Wikipedia has a long list of fabs worldwide, and unless I’m grossly mistaken there are no cutting edge ones in the UK, or even Europe. Cutting edge fabs today are <10nm, which limits you to Taiwan (TSMC), Samsung (S. Korea) or Intel (USA). The Tesla Dojo was apparently produced by TSMC on their 7nm process. Could the UK use some of the money from this project to upgrade an existing fab to 7nm? No way. The typical cost of building a new fab is in the tens of billions, so even a giant supercomputer project like this doesn’t even get close.
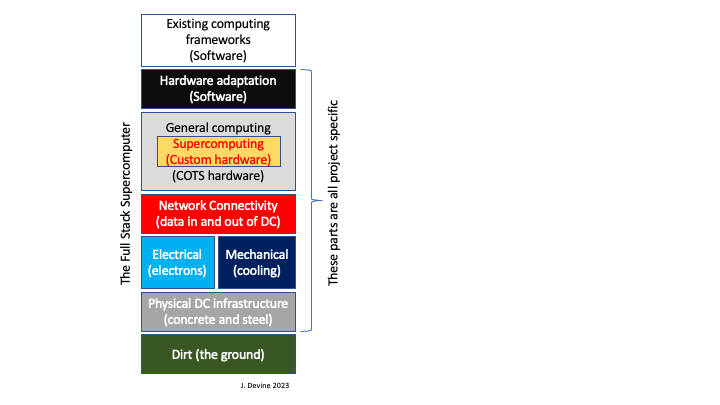
Regular readers will know that I like to abuse the term ‘Full-Stack‘, this post will be no exception. In this case the bottom of the stack is quite literally dirt under a data centre. The top as always is a bunch of software that interfaces with humans and other machines.
If the UK can’t bake it’s own chips, what is the next best thing?
NVIDIA is the current leader in AI hardware by some margin. They are a licensee of ARM, a UK centric (and once UK listed) CPU design company. One approach would be to throw money at NVIDIA for their hardware, put it in racks and call it a UK supercomputer, and if the wafers have ARM cores on them too, call it a win. It may also distract from the fact that ARM are planning to list in the US when they de-merge from Softbank.
The approach taken by Tesla was to use (more or less) RISC-V, a relatively new architecture that is based on an open standard, and increasingly the biggest competitor to ARM. This is a fundamentally different approach, which is more flexible, requires a bit more knowledge and experience on behalf of the chip designer, but looks like the way things are going in the future. The business model for RISC-V chips is very similar to ARM, you can go to a company such as SiFive and get them to design you a custom core, which you then need to get fabricated. RISC-V is really easy to get started with (not that I’m going to be designing a supercomputer myself) – you can check out this workshop I ran a few years ago about building your own chip on an FPGA. I recently read a fantastic article about Tensortorrent, who are aiming to be a specialist AI hardware house, using open RISC-V architecture as a base. If successful, this approach could be the x86 of AI.
Another option would be to throw large amounts of money at one of a small number of UK AI silicon start-ups such as Cerebras who have recently unveiled their first commercial installation. This has some advantages (domestic IP, ‘wafer scale’ deployment) and some disadvantages (custom software tooling required to run your models on it). Technically, the fundamentals are very similar to a RISC-V approach, except that the platform is entirely proprietary. There is a non-negligible risk that such a system would become obsolete in a VHS/Betamax if more players (national and corporate) go down the RISC-V route which seems likely. Of course the VCR situation isn’t exactly applicable, as it will probably always be possible to write a software interposer layer to run whatever the latest open RISC-V platform code is on a fully proprietary architecture, but this is likely to mean layers on layers which is a bad engineering idea.
What should the UK do? Given the success of ARM, it would be tempting to throw money at them and/or NVIDIA in some combination. However, if the objective is to boost domestic industry and build a network of skilled individuals who can design cutting edge AI hardware, a RISC-V based approach seems like the right call today.
What else do you need for a supercomputer?
All computers need a case, and for a supercomputer this means a data centre, or part of a data centre, filled with racks. Though I’ve never actually built a whole one from scratch myself (yet), I’ve worked on a few designs over the years. The fundamentals requirements are electricity and data connectivity (fiber), otherwise it will need cooling and some logistics (to move the hardware in, and upgrade it). A well designed data centre can last a long time, much longer than the hardware inside it.
One of the most interesting trends in the data centre world over the last few years has been the move to DC power distribution. Google have their own architecture that runs at 48V. There are significant savings to be made by not having each computer equipped with two (or more) redundant AC/DC converters, both in terms of money and energy.
Some design questions to answer
Cooling – water cooling is going to be necessary at these energy densities. It gives the opportunity for heat rejection/recovery that could say heat a swimming pool. Would anyone like a new leisure centre?
How big should the box be? The minimum size of Dojo is 10 cabinets (19″ racks). You would probably want at a few extra rows of racks and cooling, as we never quite know how the insides of our data centres will evolve. Plus some office space for human operators and a logistics bay or two.
Is this a standalone facility or part of another data centre/complex? Of course the cheapest option would be to find an unused corner in an existing data centre with spare power and cooling, though finding a couple of MW of spare power will be challenging even in the largest of facilities.
Overall project – How long will it take to build? I don’t know how long custom CPU core development takes, but to build a datacenter from scratch is about 2-3 years give or take a few months and the overhead for local planning processes.
What about staffing? How much of the budget should be allocated to:
- Building the facility
- Designing the chips
- Building the chips
- Software to run the chips (infrastructure)
- Actual research to be done on the chips
- Maintenance and upkeep for the lifetime of the facility
- Electricity bills
The fundamental question is what will be the Total Cost of Ownership of such a project, including end of life disposal.
And of course we aren’t just building a computer to sit idle. Will it be a facility that people (researchers) can ask to use? One example of shared computer infrastructure is the CERN WLGC. A quick look around the WLGC wiki shows the many layers of management, governance and operation for such an undertaking, though clearly this AI supercomputer would be a little bit simpler having a national rather than international character. Who will manage operation and access, and how will this be done? It’s clearly a case that will require an organisation to oversee, going beyond the scope of the project to build the machine in the first place. The broader question is should a new organisation be created, or can an existing research/academic structure be co-opted to run this new behemoth?
All fascinating questions, we may get to see the answers if HM Treasury ever green lights a project, rather than just a pot of money.
Full stack: the lower levels in review
Starting from the bottom up, your data centre needs a physical location. Yes, even cloud infrastructure still lives somewhere here on earth for the time being. Your site needs:
- Enough space for however many racks you wish to install, you can always go multistorey (planning permission dependant)
- Electricity (Dojo consumes up to 2MW, for reference)
- Permission to make noise, as 2+MW of cooling fans and chillers are noisy.
- Water (You will need a reasonable amount to fill up, much more if you employ evaporative cooling)
- Fibres, because you will need internet connectivity.
- Road network connectivity, because you aren’t going to deliver anything or anyone by helicopter.
Physical infrastructure:
- A large concrete slab for everything to go on.
- Walls, which can be either blockwork or concrete depending on structural loads, the number of storeys etc.
- Roof, supported on either steel or concrete.
- Drainage and rainwater connections
- Your own High Voltage substation
- A decent fence, because you don’t want just anyone coming to your data centre.
Electrical and Mechanical systems: Just like your desktop or laptop computer has a really annoying fan, and an equally annoying power cord, the same goes for your data center. The general rule here is if you need one of something to function, you actually need at least 2 of them to function reliably. You can multiply everything in the list below by 2N, or in some cases even 2N+1. The level of reliability offered by data centres is classified in Tiers, rangining from the lowest at 1, to the highest at 4, which generally includes at least 2 of everything and physical separation of systems so that a fire or failure in one room doesn’t bring your entire operation down. As a practical minimum I’d suggest:
- Two complete, independent electrical high voltage connections (if you are serious about reliability). High voltage in this domain would typically be anywhere from 11kV to 66kV.
- Transformers to go from high voltage down to 230/400V (for europe, 110/220V for the US and other parts of the world).
- Electrical switchboards to turn your single 3200A circuit from a 2 MVA transformer into lots of smaller circuits.
- UPS (uninterruptible power supply), typically this is comprised of some power electronics and a lot of batteries. It is critical if you have a power glitch, or need to keep everything running and cooled when changing from one of your supplies to the other.
- Diesel generators, because even the most reliable electrical networks still fail from time to time and you wouldn’t want to lose any precious calculations.
- Power Distribution Units (PDU’s), which is how you distribute the power to individual racks containing computers. This may also include AC/DC conversion if you go for a DC data centre design.
- Chillers or cooling towers, which can turn hot into cold via the addition of (electrical) energy and water.
- Chilled water, to distribute the cooling around your computer racks – NB this is the only thing that is generally installed as a unique item. There is almost never space for the installation of two full sets of cooling pipes in a data centre.
- Air conditioning, depending upon your computer architecture you may be able to cool your racks with air (that is in turn cooled by the chilled water). This is viable up to a few kW of heat dissipation per rack, but to really go to high power densities water to the rack is essential. Air conditioning will be provided by Air Handling Units (AHU’s) and/or CRAC units (Computer Room Air Conditioners), which are the same but smaller and typically designed to throw cold air out into a rack room false floor. In this case we are almost certainly looking at more than 20kW of load per rack, at which point water cooling for the rack is necessary and the air conditioning is only for human comfort and auxiliary systems.
- Fire detection, normally via ‘VESDA’, Very Early Smoke Detection Apparatus – a system of vacuum tubes that sample the air and can tell if it contains smoke. The sooner you detect the fire, the sooner you can take action to stop it and the lower the probability of major damage.
- Sprinklers or other gas based fire suppression (depends on your jurisdiction and the assessed risk of fire spreading between parts of your data centre).
- Lighting, because you need to have humans walking round the building to build it and install/maintain your computers.
- Comfort heating, there will probably be an office or two for humans. Computers can generate their own heat.
Network connectivity: Here we will need more than Wi-Fi or a tethered cell phone to provide access to the internet and/or our other data centres.
- As a sensible minimum you will need two incoming optical fibres, ideally following diverse routes (i.e. not running in the same trench down the same road… because diggers have a habit of severing both simultaneously!).
- You will be buying network connectivity from someone, unless you happen to also be your own Internet Service Provider (ISP). This means that you will need to provide them dedicated space inside your data centre to house their equipment that connects to the fiber and provides you somewhere to plug in. This space is sometimes called an MMR (Meet Me Room) or Comms room, and it may be a whole room, or a subdivided space with a series of cages, with one per supplier/one per supplier connection point. A design tip, don’t put your MMR’s next to each other if it can be avoided.
- Internal data connectivity, this can be provided by copper cables (Cat 6A/Cat 7) up to 10gbit, but increasingly fibre is also used within the data centre to provide communications in/out of racks, and also between racks. The cost of fibre connectivity can be significantly higher than copper, as the splicing and termination equipment (opto-electronic transceivers) are more costly.
- You will need lots of cable trays to run these optical fibers and ethernet cables between racks, rooms and the MMRs. A design tip, put power cabling under the floor and data cabling suspended from the ceiling. You are very unlikely to change the power installation after you are up and running, but data cabling is more likely to require changing as the content of the data centre evolves.
This is a lot. What if i can’t do it all myself?
There are plenty of companies that specialise in end-to-end data centre construction as a discipline, such as Equinix. For those building supercomputers there is a niche within this market generally referred to as HPC, with a few large incumbents such as HP, Fujitsu and IBM. There are also many generalists who can also put them together, to list a couple Arup (my former employer), and AECOM (who I’ve worked with in the past).
